資料來源#
摘要#
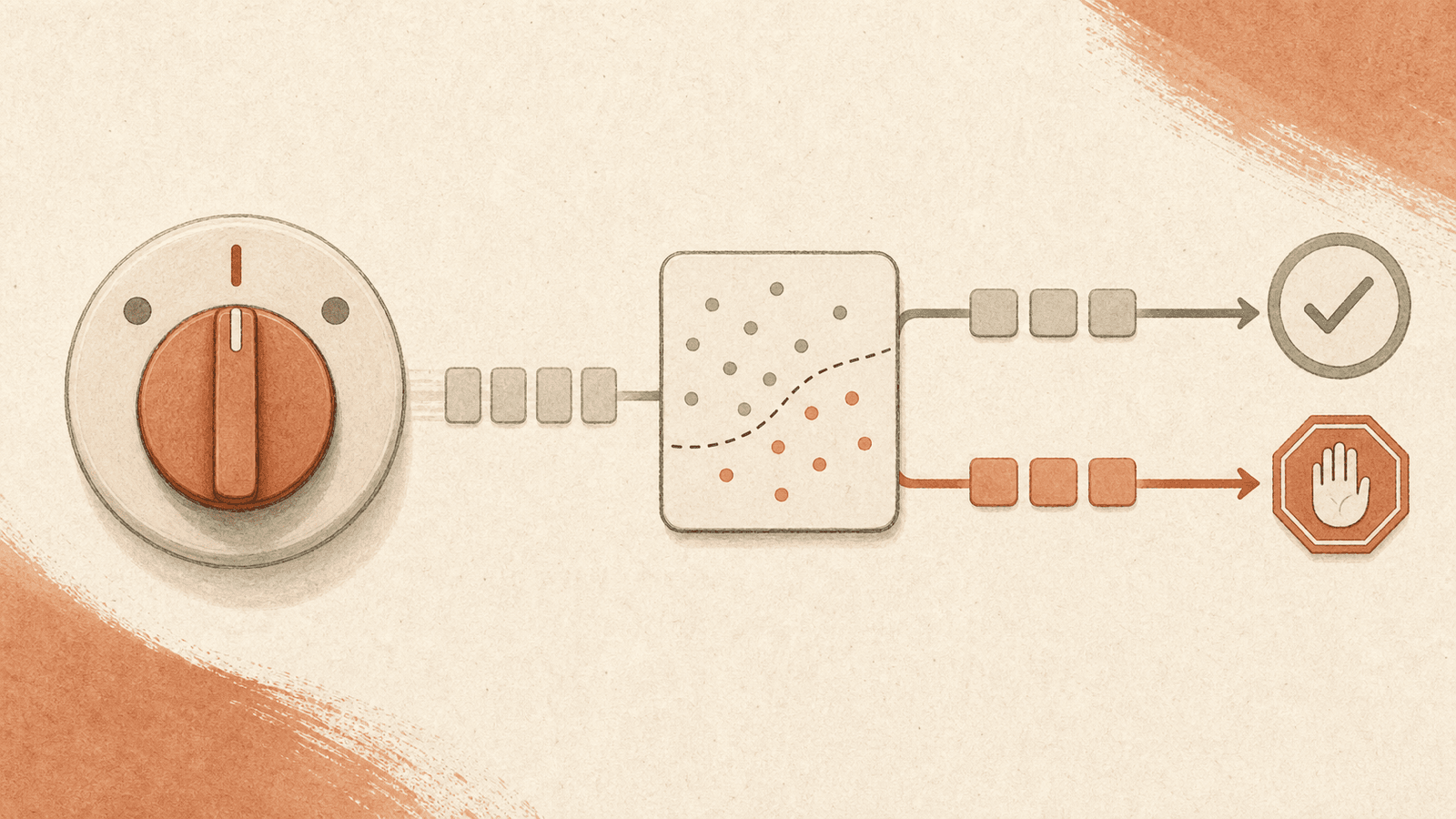
Auto mode 是 Claude Code 中的一種權限模式,它將每次 tool call 的批准委託給 classifier,定位於三點安全性光譜的中間:預設 (每次寫入/bash 都會進行 prompt) → auto mode (classifier 批准安全操作、阻擋風險操作,最後升級為 prompt 詢問) → --dangerously-skip-permissions (不進行任何檢查)。最初作為技術預覽版在 Team plan 上推出;隨後與 Opus 4.7 一同開放給 Max 使用者;並與 Sonnet 4.6 和 Opus 4.6 相容。
細節#
Mechanism#
在每次 tool call 執行之前,classifier 會對其進行檢查並返回三種結果之一:
- 安全 (Safe) → tool call 自動繼續執行,不進行 prompt。
- 有風險 (Risky) → 阻擋。Claude 會被引導嘗試其他方法。
- 重複被阻擋 (Repeatedly blocked) → 如果 Claude 堅持執行不斷被阻擋的操作,最終會向使用者呈現權限 prompt。
classifier 針對的是 Anthropic 定義為具有潛在破壞性的類別:大量檔案刪除、敏感資料外洩以及惡意程式碼執行 (完整清單維護在 Claude Code 的 permission-modes 文件中)。
Residual Risk#
Auto mode 降低了 相對於 --dangerously-skip-permissions 的風險,但並未完全消除。兩種已知的失效模式:
- 意圖模糊 (Ambiguous intent):classifier 無法判斷某個操作是否為良意。
- 缺失環境 context:classifier 不清楚特定部署的風險層面 (例如:共享資料庫、生產環境的 bucket)。
在這兩種情況下,classifier 都可能放行某些高風險操作。相反地,它有時也可能阻擋良意操作。即使開啟了 auto mode,Anthropic 仍然建議使用隔離環境。
Cost and Latency#
對每個 tool call 的 token 消耗、成本和延遲影響很小 (classifier 在行內執行)。但並非為零。
Availability and Toggles#
- 技術預覽版推出:Claude Team plan;在接下來的幾天內 (自原始貼文發布起) 推廣至 Enterprise 和 API 方案。
- 擴展至 Max 使用者,與 Opus 4.7 的發布同步 (參見 Claude Opus 4.7)。
- 在 Claude desktop app 上預設停用;管理員可透過 Organization Settings → Claude Code 進行切換。
- Managed settings 停用:在 managed settings 中將
"disableAutoMode"設定為"disable",以關閉 CLI 和 VS Code 擴充功能中的此功能。 - 開發者啟用:
- CLI:
claude --enable-auto-mode,然後使用Shift+Tab切換至該模式。 - Desktop / VS Code 擴充功能:在 Settings → Claude Code 中啟用,並在 session 期間從權限模式下拉選單中進行選擇。
- CLI:
Intended Use Case#
Auto mode 的存在是因為 Claude Code 的預設設定非常保守 —— 每次檔案寫入與 bash 指令都會進行 prompt。這種安全性設計使得無人值守 (unattended) 的長時間執行任務變得不切實際:你無法啟動一個需要數小時的重構後就轉身離開。Auto mode 是一條折衷之路:提供中斷更少的長時間任務執行,同時又不需要無條件信任 Claude 對破壞性操作的判斷。
這呼應了 Claude Code Best Practices 中的 "fan-out 與無人值守執行" 擴充模式 —— 這是一個先前被迫在審批疲勞與 --dangerously-skip-permissions 之間做二選一的既有使用場景。
Non-Interactive Mode Interaction#
當 Claude Code 以非互動方式 (claude -p) 執行時,沒有使用者可以回答權限 prompt。根據 Claude Code Best Practices, auto mode 在非互動模式下若重複被阻擋將會中止,而不是懸掛在一個無法回答的 prompt 上 —— 這保留了 best-practices 指南中描述的 fan-out 和 pre-commit-hook 使用場景。
相關連結#
- Verification as the New Bottleneck — auto-mode 的 classifier 將驗證負擔轉移到審批時的關卡攔截
- Claude Code Best Practices — auto mode 是權限章節中 "基於 classifier 的批准" 項目的實現;它與
/clear、session 管理和驗證驅動開發相結合,促成了該文章中的擴充模式 - Claude Opus 4.7 — Opus 4.7 的發布將 auto mode 的可用性擴展到 Max 使用者
- Agent Harness Engineering — auto mode 是一種 harness 等級的安全不變量:以機械式的方法強制執行破壞性操作的邊界,而非透過 prompt 建議。符合 OpenAI 的 Codex harness 研究結論中 "強制執行不變量,而非實現" 的原則
- LLM-Driven Vulnerability Research — 基於 classifier 的事前檢查是一種防禦模式,類似於 vulnerability-research scaffold 中的驗證 agent;兩者皆使用二次模型傳遞來過濾主要 agent 的操作
- Hermes Agent — 不同的批准模型設計點:Hermes 使用針對特定模式的批准 (
once/session/always/deny) 而非 classifier,並在 container backend 底下停用危險指令檢查,其基本原則是 "容器即為安全邊界"。折衷方案:以每個映像檔的規範取代每次指令的審計 - Agent Loop Pattern — auto mode 是 AFK loops 的先決條件;否則每次 tool call 都會因為 prompt 而阻擋 loop 的進行。Boris Cherny 的
/loop工作流程需要依賴基於 classifier 的閘控才能正常運作 - Harness Shrinkage as Models Improve — Cat Wu 預測,隨著模型能可靠地執行正確操作,權限模式、人工介入 (human-in-the-loop) 及靜態指令驗證都將變得 "沒那麼重要";auto mode 是朝向 harness 縮減軌跡中的 harness 資產之一
- Human-AI Accountability Redesign — auto mode 的 classifier 是 HBR 的問責制規範中 "決策權" 子領域的具體案例:定義了 agent 可以自主執行什麼,以及需要人類批准什麼
- Agentic Misalignment (AM) — 受 classifier 閘控的工具使用是針對 agentic misalignment 層面的一種緩解措施;這與模型側的緩解措施 (如 Model Spec Midtraining (MSM)) 形成互補
- AI Brain Fry — 將人工審查集中在高風險的決策點,而非過濾每次操作,是 auto mode 的 classifier 閘控所實施的監管疲勞緩解方案
- MCP and Computer Use — auto mode 閘控的底層;classifier 透過相同的風險視角評估 MCP 呼叫和 computer-use 操作
- Agentic Prompt Injection — 受 classifier 閘控的批准是 constitutional-classifier 防禦的部署實例,該防禦應用於操作邊界而非輸入邊界
- Capability-Gated Model Fallback — 在查詢邊界使用相同的 classifier 閘控概念:Fable 5 在標記為網絡/生物/提煉主題時換入較弱的模型 (Opus 4.8),而不是直接阻擋 tool call
- Autonomous Defense — "警報佇列最前端的模型" 是 SOC 中與 auto mode 的 classifier 在人類看到之前對 tool calls 進行分類篩選的對應物
待解決的問題#
- classifier 在例行但激進的重構 (例如:大檔案重新命名、
rm建置產物) 上的誤判率 (false-positive rate) 是多少? - 在缺乏環境 context 的情況下,classifier 對自訂 tools / MCP 伺服器的泛化能力如何?
- classifier 的決策邊界是否足夠詳細記錄且穩定,以便讓安全性敏感的組織進行認證,還是它本質上是一個黑盒子,其行為會隨著更新而 drifts?
- 將 auto mode 開放給 API 使用者是否會改變其校準 —— classifier 會針對重度自動化使用進行重新訓練,還是保持不變?
- 與 OS 等級的沙箱技術 (在 Claude Code Best Practices 中與 auto mode 一同提及) 相比,它的 defense-in-depth 架構如何?何時應該將兩者分層部署?
衍生內容#
- Opus 4.6 → 4.7 Changes and Multi-Agent Coding Considerations — auto mode 作為無人值守 multi-agent fan-out 的 defense-in-depth 層
資料來源#
- Auto mode for Claude Code
- Introducing Claude Opus 4.7 — 擴展至 Max 使用者
Cited by 21
- Agent Harness Engineering
Patterns for scaffolding long-running LLM agents: environment design, progressive context disclosure, mechanical archit…
- Agent Loop Pattern
`/loop` (cron-scheduled) and Ralph Wiggum (backlog-draining) loops as next-generation agent primitive; AFK execution, p…
- Agentic Prompt Injection
Direct and indirect injection of malicious instructions into an agent; LLMs cannot reliably distinguish information fro…
- AI Brain Fry
Kropp et al. 2026/03: mental fatigue from excessive AI oversight increases minor errors +11%, major errors +39%; cognit…
- Autonomous Defense
Running security operations at the speed of AI-accelerated threats: put a model at the front of the alert queue, automa…
- Capability-Gated Model Fallback
Fable 5's safeguard architecture: classifiers detect cyber / bio-chem / distillation queries and route the response to…
- Claude Code
Anthropic's agentic coding product; created by Boris Cherny late 2024; TypeScript/React; CLI/desktop/web/mobile/IDE sur…
- Claude Code Best Practices
Anthropic's guide to effective Claude Code usage: context management, verification-driven development, explore→plan→cod…
- Claude Opus 4.7
GA frontier model from Anthropic; direct upgrade to 4.6 at same price; literal instruction following, 1.0–1.35× tokeniz…
- Harness Shrinkage as Models Improve
Prompt scaffolding shrinks each model release; Cat Wu's pruning discipline; Boris Cherny "100 lines of code a year from…
- Hermes Agent
Nous Research's CLI agent + Gateway daemon (Telegram/Discord/Slack/WhatsApp); AGENTS.md/SOUL.md context split, bounded…
- Human-AI Accountability Redesign
HBR five-pillar prescription: span-of-control redesign, role redesign, performance management reset, decision-rights/es…
- Human-in-the-Loop Boundaries
Humans belong at allocation, understanding, design-concept, risk, and accountability boundaries; they slow the system d…
- LLM-Driven Vulnerability Research
Claude Mythos Preview's emergent cybersecurity capabilities: autonomous zero-day discovery, full exploit chains, and An…
- MCP and Computer Use
Anthropic's two complementary connector mechanisms: MCP for structured programmatic access (Salesforce/Drive/Gmail/Slac…
- AI Engineering & Agent Tooling
Map of Content for the ai-engineering domain — 36 concepts. Curated entry point; see Home for all domains.
- Model Spec Midtraining (MSM)
New training phase between pretrain and AFT: train base model on synthetic docs discussing the Model Spec; controls AFT…
- Open Questions Backlog
_96 pages with open questions, as of 2026-06-14._
- Opus 4.6 → 4.7 Changes and Multi-Agent Coding Considerations
4.6→4.7 delta table + six hazards for multi-agent coding teams: role-based model selection, prompt re-tuning, harness i…
- Orchestration vs Employee Framing: Reconciling the Founder's Playbook with HBR's Accountability Evidence
Reconciles the Founder's Playbook orchestration framings with HBR Kropp et al.'s accountability evidence; "orchestratio…
- Verification as the New Bottleneck
Fiona Fung: coding is no longer the bottleneck — verification, review, maintenance are; shift-left; TDD loses its tax;…
Related articles
- Harness Shrinkage as Models Improve
Prompt scaffolding shrinks each model release; Cat Wu's pruning discipline; Boris Cherny "100 lines of code a year from…
- Claude Code Best Practices
Anthropic's guide to effective Claude Code usage: context management, verification-driven development, explore→plan→cod…
- Agent Harness Engineering
Patterns for scaffolding long-running LLM agents: environment design, progressive context disclosure, mechanical archit…
- Claude Opus 4.7
GA frontier model from Anthropic; direct upgrade to 4.6 at same price; literal instruction following, 1.0–1.35× tokeniz…
- Agent Loop Pattern
`/loop` (cron-scheduled) and Ralph Wiggum (backlog-draining) loops as next-generation agent primitive; AFK execution, p…