Sources#
Summary#
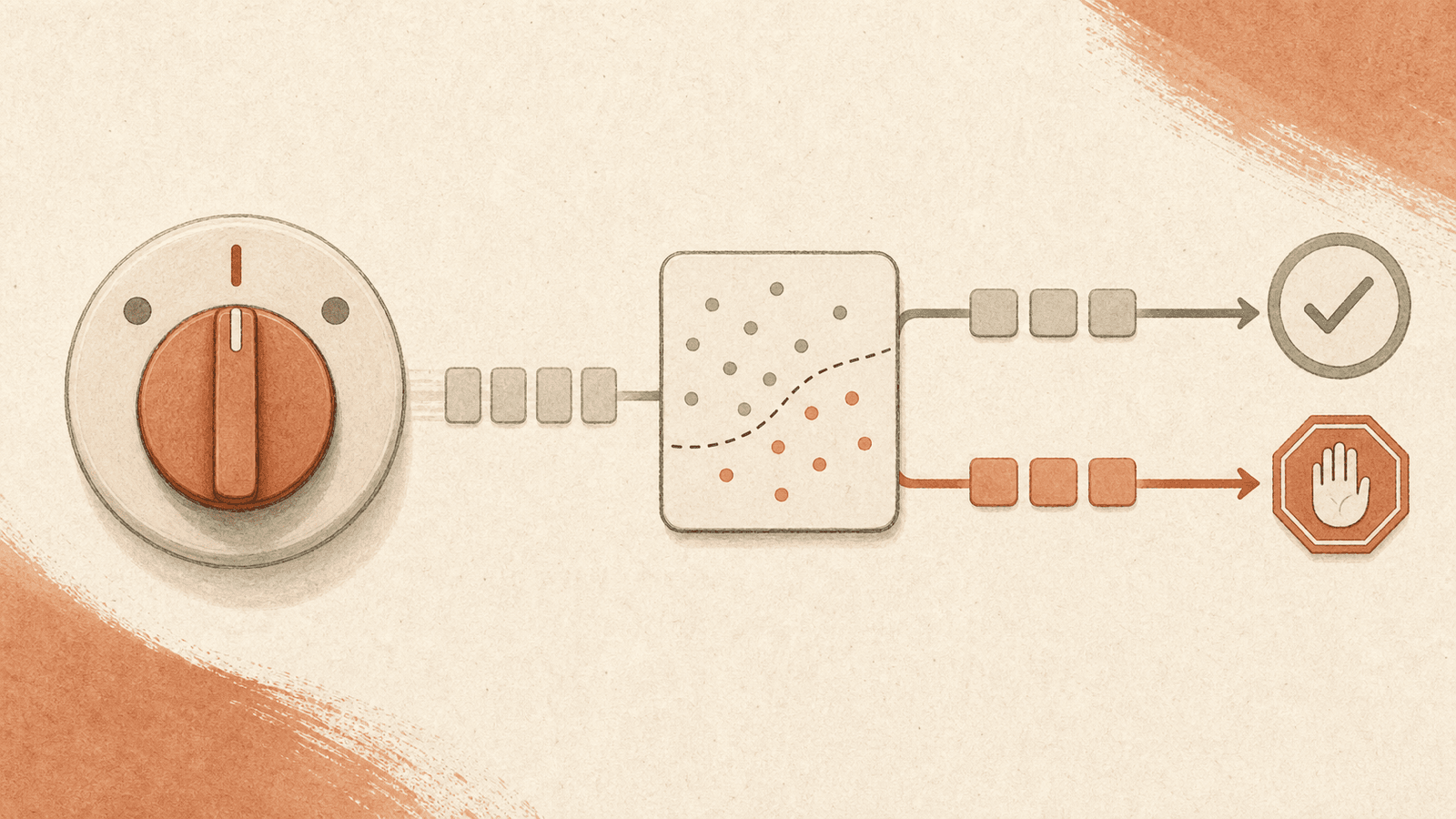
Auto mode is a permissions mode in Claude Code that delegates per-tool-call approval to a classifier, positioned as the middle of a three-point safety spectrum: default (prompt on every write/bash) → auto mode (classifier approves safe, blocks risky, eventually escalates to prompt) → --dangerously-skip-permissions (no checks). Introduced as a research preview on the Team plan; extended to Max users alongside Opus 4.7; compatible with Sonnet 4.6 and Opus 4.6.
Details#
Mechanism#
Before each tool call runs, a classifier inspects it and returns one of three outcomes:
- Safe → tool call proceeds automatically, no prompt.
- Risky → blocked. Claude is redirected to try a different approach.
- Repeatedly blocked → if Claude insists on actions that keep getting blocked, a permission prompt is eventually surfaced to the user.
The classifier targets categories that Anthropic characterizes as potentially destructive: mass file deletion, sensitive data exfiltration, and malicious code execution (full list is maintained in the Claude Code permission-modes docs).
Residual Risk#
Auto mode reduces risk vs. --dangerously-skip-permissions but does not eliminate it. Two documented failure modes:
- Ambiguous intent: classifier can't tell whether an action is benign.
- Missing environment context: classifier doesn't know the deployment-specific risk surface (e.g., a shared DB, a production bucket).
In both cases the classifier may allow some risky actions through. Conversely, it may occasionally block benign actions. Anthropic continues to recommend isolated environments even with auto mode on.
Cost and Latency#
Small impact on token consumption, cost, and latency per tool call (classifier runs inline). Not zero.
Availability and Toggles#
- Research preview launch: Claude Team plan; rolling to Enterprise and API plans in the coming days (as of the source post).
- Extended to Max users alongside Opus 4.7 launch (see Claude Opus 4.7).
- Disabled by default on the Claude desktop app; admins toggle via Organization Settings → Claude Code.
- Managed disable: set
"disableAutoMode": "disable"in managed settings to turn it off for CLI and VS Code extension. - Developer enable:
- CLI:
claude --enable-auto-mode, then cycle to it withShift+Tab. - Desktop / VS Code extension: enable in Settings → Claude Code, select from the permission-mode dropdown in-session.
Intended Use Case#
Auto mode exists because Claude Code's default is deliberately conservative — every file write and bash command prompts. That safety makes unattended long-running tasks impractical: you can't kick off a multi-hour refactor and walk away. Auto mode is the middle path: long tasks with fewer interruptions, without unconditionally trusting Claude's judgment on destructive actions.
This mirrors the "fan-out and unattended runs" scaling patterns in Claude Code Best Practices — a pre-existing use case that previously forced a binary choice between approval fatigue and --dangerously-skip-permissions.
Non-Interactive Mode Interaction#
When Claude Code runs non-interactively (claude -p), there is no user to answer a permission prompt. Per Claude Code Best Practices, auto mode aborts on repeated blocks in non-interactive mode rather than hanging on an un-answerable prompt — preserving the fan-out and pre-commit-hook use cases described in the best-practices guide.
Connections#
- Verification as the New Bottleneck — auto-mode's classifier shifts the verification burden to approval-time gating
- Claude Code Best Practices — auto mode is the resolution of the permissions section's "classifier-based approval" bullet; together with
/clear, session management, and verification-driven development it enables the scaling patterns in that article - Claude Opus 4.7 — Opus 4.7 launch extended auto mode availability to Max users
- Agent Harness Engineering — auto mode is a harness-level safety invariant: enforce destructive-action boundaries mechanically, not via prompt advisories. Fits the "enforce invariants, not implementations" principle from OpenAI's Codex harness findings
- LLM-Driven Vulnerability Research — classifier-based pre-flight is a defensive pattern analogous to the validation agent in the vulnerability-research scaffold; both use a secondary model pass to filter the primary agent's actions
- Hermes Agent — different approval-model design point: Hermes uses per-pattern approvals (
once/session/always/deny) instead of a classifier, and disables dangerous-command checks under a container backend on the principle that "the container is the security boundary." Trade: per-image discipline replaces per-command auditing - Agent Loop Pattern — auto mode is a precondition for AFK loops; without it, every tool call would block the loop on a prompt. Boris Cherny's
/loopworkflow depends on classifier-based gating to be usable - Harness Shrinkage as Models Improve — Cat Wu predicts permission modes / human-in-the-loop / static command verification all become "less important" as models reliably do the right thing; auto mode is one of the harness assets on the trajectory toward shrinkage
- Human-AI Accountability Redesign — auto mode's classifier is a concrete instance of the "decision rights" subfront in HBR's accountability prescription: define what the agent does autonomously vs requires human approval
- Agentic Misalignment (AM) — classifier-gated tool use is one mitigation against agentic misalignment surfaces; complementary to model-side mitigations like Model Spec Midtraining (MSM)
- AI Brain Fry — concentrating human review on high-stakes decision points rather than every action is the oversight-fatigue mitigation auto mode's classifier-gating operationalizes
- MCP and Computer Use — the substrate auto mode gates; classifier evaluates MCP calls and computer-use actions through the same risk lens
- Agentic Prompt Injection — classifier-gated approval is a deployed instance of the constitutional-classifier defense applied at the action boundary rather than the input boundary
- Capability-Gated Model Fallback — the same classifier-gating idea at the query boundary: Fable 5 swaps in a weaker model (Opus 4.8) on flagged cyber/bio/distillation topics instead of blocking a tool call
- Autonomous Defense — "a model at the front of the alert queue" is the SOC analogue of auto mode's classifier triaging tool calls before a human sees them
Open Questions#
- What false-positive rate does the classifier have on routine-but-aggressive refactors (e.g., large-file renames,
rmof build artifacts)? - How well does the classifier generalize to custom tools / MCP servers where it lacks environment context?
- Is the classifier's decision boundary documented/stable enough for security-sensitive orgs to certify, or is it effectively a black box whose behavior drifts with updates?
- Does extending auto mode to API users change its calibration — is the classifier retrained for automation-heavy use, or held constant?
- Compared to OS-level sandboxing (mentioned in Claude Code Best Practices alongside auto mode), what's the defense-in-depth story? When should both be layered?
Derived#
- Opus 4.6 → 4.7 Changes and Multi-Agent Coding Considerations — auto mode as defense-in-depth layer for unattended multi-agent fan-out
Sources#
- Auto mode for Claude Code
- Introducing Claude Opus 4.7 — extension to Max users
Cited by 21
- Agent Harness Engineering
Patterns for scaffolding long-running LLM agents: environment design, progressive context disclosure, mechanical archit…
- Agent Loop Pattern
`/loop` (cron-scheduled) and Ralph Wiggum (backlog-draining) loops as next-generation agent primitive; AFK execution, p…
- Agentic Prompt Injection
Direct and indirect injection of malicious instructions into an agent; LLMs cannot reliably distinguish information fro…
- AI Brain Fry
Kropp et al. 2026/03: mental fatigue from excessive AI oversight increases minor errors +11%, major errors +39%; cognit…
- Autonomous Defense
Running security operations at the speed of AI-accelerated threats: put a model at the front of the alert queue, automa…
- Capability-Gated Model Fallback
Fable 5's safeguard architecture: classifiers detect cyber / bio-chem / distillation queries and route the response to…
- Claude Code
Anthropic's agentic coding product; created by Boris Cherny late 2024; TypeScript/React; CLI/desktop/web/mobile/IDE sur…
- Claude Code Best Practices
Anthropic's guide to effective Claude Code usage: context management, verification-driven development, explore→plan→cod…
- Claude Opus 4.7
GA frontier model from Anthropic; direct upgrade to 4.6 at same price; literal instruction following, 1.0–1.35× tokeniz…
- Harness Shrinkage as Models Improve
Prompt scaffolding shrinks each model release; Cat Wu's pruning discipline; Boris Cherny "100 lines of code a year from…
- Hermes Agent
Nous Research's CLI agent + Gateway daemon (Telegram/Discord/Slack/WhatsApp); AGENTS.md/SOUL.md context split, bounded…
- Human-AI Accountability Redesign
HBR five-pillar prescription: span-of-control redesign, role redesign, performance management reset, decision-rights/es…
- Human-in-the-Loop Boundaries
Humans belong at allocation, understanding, design-concept, risk, and accountability boundaries; they slow the system d…
- LLM-Driven Vulnerability Research
Claude Mythos Preview's emergent cybersecurity capabilities: autonomous zero-day discovery, full exploit chains, and An…
- MCP and Computer Use
Anthropic's two complementary connector mechanisms: MCP for structured programmatic access (Salesforce/Drive/Gmail/Slac…
- AI Engineering & Agent Tooling
Map of Content for the ai-engineering domain — 36 concepts. Curated entry point; see Home for all domains.
- Model Spec Midtraining (MSM)
New training phase between pretrain and AFT: train base model on synthetic docs discussing the Model Spec; controls AFT…
- Open Questions Backlog
_96 pages with open questions, as of 2026-06-14._
- Opus 4.6 → 4.7 Changes and Multi-Agent Coding Considerations
4.6→4.7 delta table + six hazards for multi-agent coding teams: role-based model selection, prompt re-tuning, harness i…
- Orchestration vs Employee Framing: Reconciling the Founder's Playbook with HBR's Accountability Evidence
Reconciles the Founder's Playbook orchestration framings with HBR Kropp et al.'s accountability evidence; "orchestratio…
- Verification as the New Bottleneck
Fiona Fung: coding is no longer the bottleneck — verification, review, maintenance are; shift-left; TDD loses its tax;…
Related articles
- Harness Shrinkage as Models Improve
Prompt scaffolding shrinks each model release; Cat Wu's pruning discipline; Boris Cherny "100 lines of code a year from…
- Claude Code Best Practices
Anthropic's guide to effective Claude Code usage: context management, verification-driven development, explore→plan→cod…
- Agent Harness Engineering
Patterns for scaffolding long-running LLM agents: environment design, progressive context disclosure, mechanical archit…
- Claude Opus 4.7
GA frontier model from Anthropic; direct upgrade to 4.6 at same price; literal instruction following, 1.0–1.35× tokeniz…
- Agent Loop Pattern
`/loop` (cron-scheduled) and Ralph Wiggum (backlog-draining) loops as next-generation agent primitive; AFK execution, p…